Elegant collaboration, part 1: programming the web
(EXPAND THIS INTRODUCTION.)
You're not alone. I'm not talking about extraterrestrial life, though. The internet is both a community and an encyclopedic resource that can be immensely useful to research and to scientific programming. Undoubtedly you use it already: for communicating with colleagues, for sharing results, for researching papers. In this chapter I would like to show you how programming the web can extend your reach, productivity, and (yes!) joy even more.
Building a reference assistant
If you're like me, you write papers in LaTeX, and add references using BibTeX. It's a good combination that is based on a charmingly vintage text- and compiler-based workflow, and that results in flawless typography and accurate citations. If you don't do LaTeX, you should; in the meantime, I will show you the very basics that you need to follow the rest of this section.
The main LaTeX file for the paper consists of lightly marked-up text:
% file montecarlo.tex
[...]
The origins of Monte Carlo integration are usually traced to the famous Metropolis paper \cite{1953JChPh..21.1087M}, which studies the equation of state of a two-dimensional system of rigid-sphere molecules.
[...]
\bibliography{monterefs} % lets LaTeX/BibTeX know that references are in file monterefs.bib
[...]
LaTeX has a special syntax to divide the document in sections, to make beautiful equations, and so on, but that does not concern us here. The references are called up with \cite commands, and they are collected in a BibTeX file of characteristic (non-LaTeX!) syntax:
% file monterefs.bib
[...]
@ARTICLE{1953JChPh..21.1087M,
author = {{Metropolis}, N. and {Rosenbluth}, A.~W. and {Rosenbluth}, M.~N. and {Teller}, A.~H. and {Teller}, E.},
title = "{Equation of State Calculations by Fast Computing Machines}",
journal = {J. Chem. Physics},
year = 1953,
month = jun,
volume = 21,
pages = {1087-1092},
doi = {10.1063/1.1699114},
}
[...]
Compiling a BibTeX file is tedious work at best; various commercial and open-source citation managers can help, but I prefer to use a web service such as NASA's ADS. ADS lets you search interactively for relevant articles using many keys (author, title, year, journal, ...); it identifies them with unique bibcodes (such as 1953JChPh..21.1087M); and it can generate their BibTeX entries with a single click. Indeed, that's where I got the Metropolis et al. entry listed above.
Even so, it takes quite a bit of link-clicking and copy-and-pasting to put together the BibTeX file for more than a few references. It would be much nicer if we could just drop ADS bibcodes in our LaTeX file, and have the corresponding BibTeX entries automatically collected for us. In this section, we will build a Python tool to do just that. We'll do it in steps, and each step will teach us something useful about programming the web and massaging its content.
- We will first learn how to grab BibTeX from ADS, which requires that we issue an HTTP request from Python. No big deal.
- Then we will collect all required bibcodes from our LaTeX file. For this we'll use regular expressions, and we will also need to understand the LaTeX/BibTeX workflow.
- Last, we will put the two steps together, and write a Python script that gets references from ADS and appends them to our BibTeX file as we add new citations to our document. We will be nice to ADS, and keep track of the references we already have, so we don't ask for them twice.
HTTP requests: grabbing references from ADS
Let us look for the Metropolis paper on ADS. We begin at http://ads.harvard.edu and search for "Metropolis 1953"; this yields a page that lists two possible results:
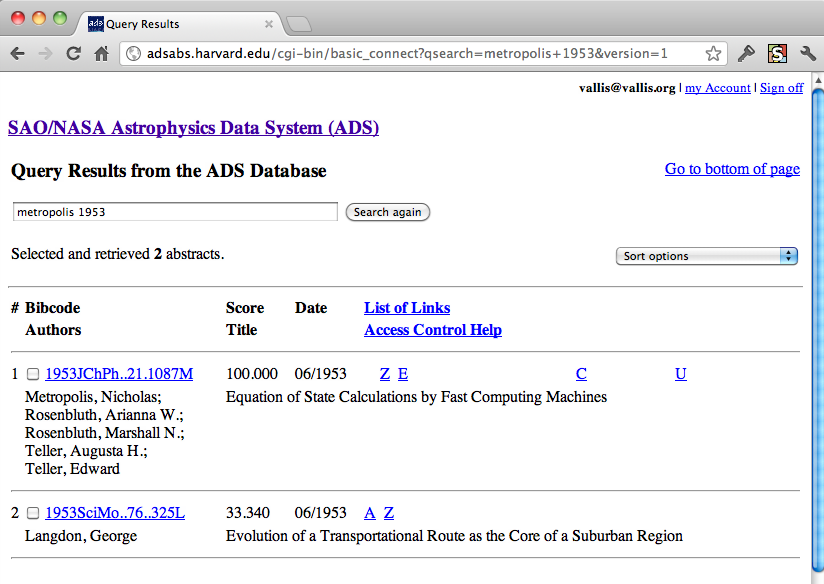
ADS search results for "Metropolis 1953".
We click on the first link to get the full ADS record for our paper:
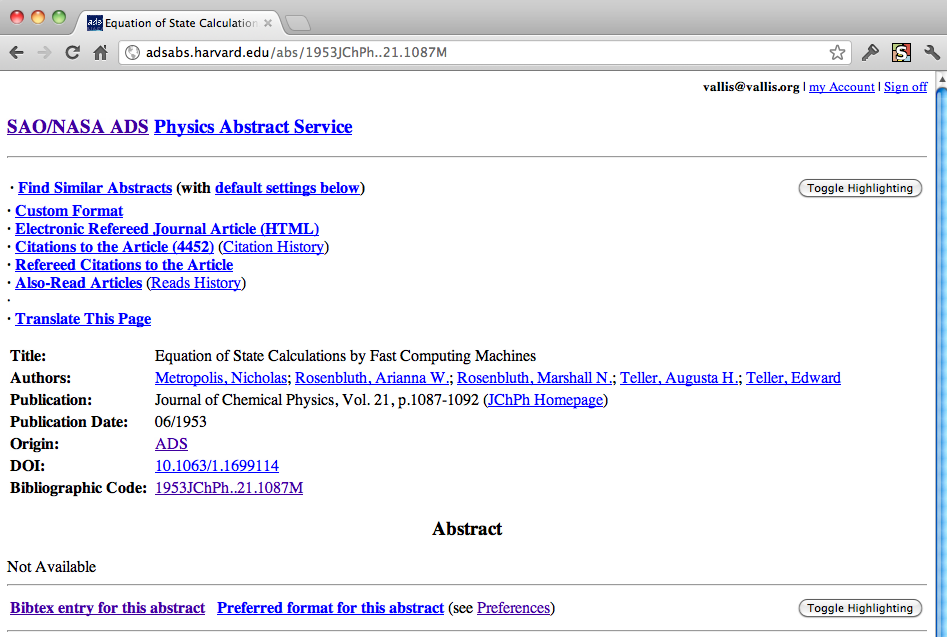
ADS record for the Metropolis et al. 1953 paper.
From here we can access the full text of the article, all of its citations, other publications by its authors, and more. But to get our desired BibTeX code we click on "Bibtex entry for this abstract." Here it is!
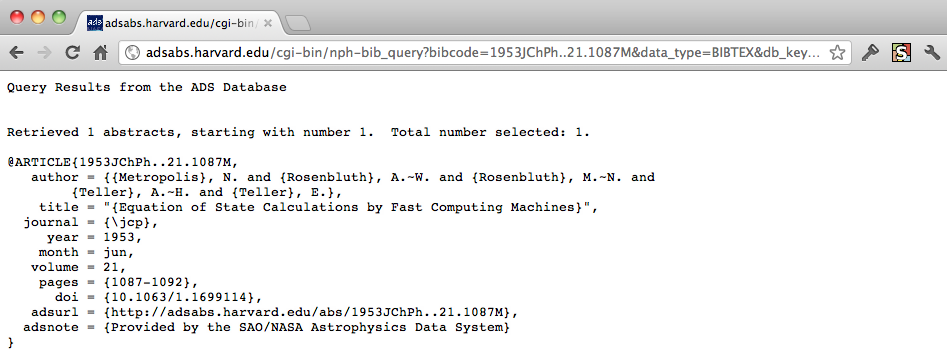
ADS BibTeX record for the Metropolis et al. 1953 paper.
Remember our goal: we want Python to get this BibTeX for us, so we'll need a more machine-friendly description of the job than a sequence of clicks. What do the clicks do? In this age of Google Mail and Maps, they could be interacting with the website in complex ways, but in this case it seems that they are just instructing the browser to visit a specific web address (technically, a Uniform Resource Locator, or URL), which we can read off from the browser's address bar. For the ADS record of the Metropolis paper, the URL is
http://adsabs.harvard.edu/abs/1953JChPh..21.1087M [URL 1]
which features prominently the ADS bibcode 1953JChPh..21.1087M! So we conjecture that the ADS record for any paper can be obtained by pointing our browser to the URL http://adsabs.harvard.edu/abs/ + the bibcode. Indeed, trying this out with another bibcode (for instance 2011PhRvL.107s1104V) confirms our conjecture.
The URL for the BibTeX entry is a little more complicated:
http://adsabs.harvard.edu/cgi-bin/nph-bib_query?bibcode=1953JChPh..21.1087M&data_type=BIBTEX&db_key=PHY&nocookieset=1 [URL 2]
but we may still guess (and confirm) that by replacing 1953JChPh..21.1087M with any other bibcode we would get the corresponding BibTeX entry.
What's going on here? Whereas URL 1 could be understood most simply as requesting an actual file stored by the server (although that may not be what really happens), the form of URL 2 suggests that nph-bib_query is a program that is launched by the web server, that takes a few parameters (bibcode is 1953JChPh..21.1087M; data_type is BIBTEX; db_key is PHY; and nocookieset is 1), and that returns a dynamically generated webpage that did not exist before the request.
We have just reverse-engineered the HTTP Common Gateway Interface (CGI) GET method, which asks a web server to run a program with given parameters and returns its output. The URL itself encodes all necessary information: the program's location in the root directory of the website goes first, followed by "?" and by a set of key=value parameter pairs separated by &. (And this is the full story, except for a few subtleties: for instance, reserved characters such as ? and & must be percent-encoded as their hexadecimal ASCII codes %3F and %26.)
Once we know which URLs we need, it's a simple thing to get Python to behave as a browser, and fetch the corresponding page. There's surely a package for that! We could use the standard-library urllib2 module, but the requests package is even nicer. With requests, a GET request looks like this:
>>> import requests
>>> req = requests.get('http://adsabs.harvard.edu/cgi-bin/nph-bib_query?bibcode=1953JChPh..21.1087M&data_type=BIBTEX')
then we can check that the page was fetched alright:
>>> req.ok
True
and look at its contents:
>>> req.content
u'Query Results from the ADS Database\n\n\nRetrieved 1 abstracts, starting with number 1. Total number selected: 1.\n\n@ARTICLE{1953JChPh..21.1087M,\n author = {{Metropolis}, N. and {Rosenbluth}, A.~W. and {Rosenbluth}, M.~N. and \n\t{Teller}, A.~H. and {Teller}, E.},\n title = "{Equation of State Calculations by Fast Computing Machines}",\n journal = {\\jcp},\n year = 1953,\n month = jun,\n volume = 21,\n pages = {1087-1092},\n doi = {10.1063/1.1699114},\n adsurl = {http://adsabs.harvard.edu/abs/1953JChPh..21.1087M},\n adsnote = {Provided by the SAO/NASA Astrophysics Data System}\n}\n\n'
This Python Unicode string (as denoted by the u before the quotes) contains the exact text shown in the browser window in Figure 3. The "\n", of course are newline characters. We'll need to strip out everything up to @ARTICLE, but we can worry about that later.
Regular expressions: collecting citations from LaTeX
As I was saying above, the LaTeX/BibTeX workflow is old-fashioned: everything happens through text files of a few different types. A charming touch is that the latex command must be run several times whenever citations are added... it sort of needs to catch up with itself. Let me save you a trip to the LaTeX and BibTeX manuals, and tell you what actually happens.
Say we've just finished editing our LaTeX file
montecarlo.texand BibTeX filemonterefs.bib. Then we run:latex montecarlo.tex(to create a DVI file, orpdflatex montecarlo.texto go straight to PDF)latexdumps all the requested citations, as well as the name of the bibliography file that we want to use (monterefs.bib), into the auxiliary filemontecarlo.aux;bibtex montecarlobibtexreads a list of requested citations frommontecarlo.aux, finds them inmonterefs.bib(if they are there), compiles them to properly formatted text, and writes the results tomontecarlo.bbl;latex montecarlo.tex(again)latexcopies the formatted references to the bibliography section of the paper, and dumps the appropriate citation information (either sequential numbers such as "[43]", or author–year combinations such as "Vallisneri 2008") into an updatedmontecarlo.aux;latex montecarlo.tex(again)latexincludes the correct citation handles in the DVI or PDF output;we're done. Wait, already?
There are ways to automate this process, but I wanted to show you all the steps, so you can understand what goes in each file.
Back to our job then. We can extract the bibcodes for all required citations from montecarlo.aux, which includes lines of the form
% file montecarlo.aux
[...]
\citation{1953JChPh..21.1087M}
[...]
From each such line, we want only the bibcode. Ah, this is just the job for regular expressions (regexes). Regexes are a way to express patterns that describe possible sets of character strings (for instance, all "words" of 10 alphabetical characters that begin with "a"; are all dates formatted as "mm/dd/yyyy"); when a string belongs to the set described by a regex, we say that the regex matches the string. Regexes first appeared in Ken Thompson's 1970 reimplementation of the QED editor, and they have since been used in many computer languages and tools to find and extract patterns in text.
You can find a quick regex-in-Python cheatsheet below. For our purposes, we need to know only the following:
- the jack-of-all trades regex "
.*" matches any number ("*") of any character except a newline ("."); - special characters such as "
\", "{", and "}" need to be escaped with a\; - the interesting parts of a pattern (the collecting groups) that we want to extract individually can be marked off with parentheses "
(...)".
Thus the regex "\\citation\{(.*)\}" can be used to extract bibcodes from montecarlo.aux with the Python module re:
>>> import re
>>> with open('montecarlo.aux','r') as auxfile:
... re.findall(r'\\citation\{(.*)\}',auxfile.read())
['1953JChPh..21.1087M']
Here we open the file montecarlo.aux using a with statement, so that it will be closed automatically for us once we're done with it; we read its entire contents into a single string; and we use re.findall() to search the string for all occurrences of the regex, and return a list of all the matched groups. The regex is expressed as a raw string r'...', which avoids problems with backslashes (see the cheatsheet).
The adsgrab.py script
Excellent! We're ready to put everything together into a script. Follow along and read the comments carefully; they are cross-linked by numbered references to the more detailed notes below.
# file adsgrab.py
import sys,re,os
import requests
# get the filenames from the command line; we'll provide the suffixes [1]
auxfilename = sys.argv[1] + '.aux'
bibfilename = sys.argv[2] + '.bib'
# get the bibcodes from the .aux file, using our regex [2]
with open(auxfilename,'r') as auxfile:
cites = re.findall(r'\\citation\{(.*)\}',auxfile.read())
# split multiple citations, flatten resulting list of lists [3]
bibcodes = [bibcode for cite in cites for bibcode in cite.split(',')]
# if the bibtex file exists, get all the refs it already has [4]
if os.path.isfile(bibfilename):
with open(bibfilename,'r') as bibfile:
bibrefs = re.findall(r'@.*?\{(.*),',bibfile.read())
# remove them from bibcodes [5]
bibcodes = [bibcode for bibcode in bibcodes if bibcode not in bibrefs]
# this is the shortened ADS URL for the GET request
url = 'http://adsabs.harvard.edu/cgi-bin/nph-bib_query?bibcode=%s&data_type=BIBTEX'
# now open the .bib file for appending [6]
with open(bibfilename,'a') as bibfile:
# loop over bibcodes and issue GET requests, avoiding duplicates [7]
for bibcode in set(bibcodes):
request = requests.get(url % bibcode)
if request.ok:
# if the request succeeded, strip out the comments
# at the beginning, and write to the .bib file [8]
ref = re.search(r'@.*\}',request.content,re.DOTALL).group(0)
bibfile.write(ref + '\n\n')
else:
print "Can't find reference %s in ADS!" % bibcode
Notes:
- We start by getting the filenames for the
.auxand.bibfiles from the command line (remember thatsys.argv[0]will be the name of the script itself). We'll provide the filename endings. - We then get the bibcodes from the
.auxfile using the regex that we developed above. However, we need to handle the case where two or more references are cited together (e.g.,
\cite{1953JChPh..21.1087M,2005blda.book.....G}); in this case the regex extracts the bibcodes in a single lump, and we can split them at the comma using the Pythonstringmethodsplit(',').Since
split()always returns a list, we're left with a list of lists. Of the various ways to flatten it to a simple list, I like a nested list comprehension[bibcode for cite in cites for bibcode in cite.split(',')]This syntax may seem funny, but it has its logic: you can think of it as two nested
forloops:result = [] for cite in cites: for bibcode in cite.split(','): result.append(bibcode)If the BibTeX file already exists (
os.path.isfile()), we want to make a list of the references it already contains, so the don't get them again from ADS. If you look at the BibTeX syntax, you'll see that the appropriate regex to collect the bibcodes is "@.*?\{(.*),".Let's break it down: we look for strings that begin with "
@", followed by any sequence of characters (e.g., "BOOK", "ARTICLE"), followed by a left brace, another sequence of characters (the bibcode we want), followed by a comma. (The "?" makes the first ".*" non-greedy, so that it matches the shortest sequence compatible with the pattern, and it does not try to match the first brace. See the cheatsheet below.)Once we have a list of the references in the
.bibfile, we remove them from the list of.auxbibcodes with a list comprehension which includes a condition:bibcodes = [bibcode for bibcode in bibcodes if bibcode not in bibrefs]- We're ready to get the BibTeX data from ADS. We open the
.bibfile for appending, which will create it if it does not exist yet. - We loop over the list of bibcodes, which may have duplicates. To avoid repeating ourselves, we turn the list into a Python set.
We need one final regex to grab the BibTeX data only and not the initial comments ("Query Results..."). We need to match everything between the first "
@" and the last "}"; the regex "@.*\}" will do this, provided that we givere.searchthatre.DOTALLflag so that "." will match newlines as well as everything else.
Lessons learned
We're done! There were quite a few details that we had to get just right along the way, but the resulting script is very clean and expressive. (One way to converge to the right form of the regexes is to go back and forth between the interactive Python shell and the code editor, and experiment with snippets before including them in the program.) The script is also very functional, and I have been using it to great satisfaction in my everyday research work.
What you have learned in this section should help you in other situations where you need to gather data from the web programmatically: the combination of HTTP requests and regular expressions can go a long way. For some applications, you may need also another piece of the puzzle: XML-based data formats. We'll talk about that soon.
Making your website interactive with CGI scripts
(STILL TO WRITE...)
Exercises
Exercise 1 – inSPIRE
Where ADS caters to the astronomical community, INSPIRE is the preferred bibliographic service for high-energy physics. Modify our script adsgrab.py so that it accepts citations given as INSPIRE bibcodes, and gets the corresponding BibTeX data (hint: play with the form interface on the INSPIRE homepage).
For a slightly more difficult variant, accept citations given as Digital Object Identifiers (DOIs) or INSPIRE record numbers; you will need to replace the bibcode in the resulting BibTeX.
Exercise 2 – ...
(MORE EXERCISES TO COME)
Aside: a cheatsheet for regexes in Python
These are just a few basics, but there's a lot more to it (Friedl 2006).
Characters:
- all "normal" characters match themselves;
- "
." matches any character, except newlines; - special characters (such as "
.", "*", ...) need to be escaped with "\" (itself a special character); - "
\n" and "\t" are newline and tab, as in C (and Python).
Character classes:
- "
[x-y]" matches one out of a range of characters; - "
\w" and "\W" match a word character (an alphanumeric character or underscore), and a non-word character, respectively; - "
\d" and "\D" match a digit and a non-digit; - "
\s" and "\S" match a whitespace character ([ \t\r\n\v\f]) and a non-whitespace character.
Repetitions:
- "
*" matches none, one, or more of what comes immediately before; - "
+" matches one or more; - "
?" matches none or one; - "
{n}" matches \(n\) occurrences; "{m,n}" matches \(m\)–\(n\) occurrences.
Groups:
- "
(...)" mark the edges of specially designated collecting groups that can be extracted individually from the match; - in replacement strings (see below), collecting groups are denoted as "
\1", "\2", and so on.
More:
- "
$" and "^" denote the beginning and end of a line; - "
*?", "+?", and "??" are non-greedy versions of the repetition operators, which find the shortest (rather than longest) match for a pattern; for instance, "A.*c" will match the entire "AbcAbc", while "A.*?c" will match "Abc"; - "
|" is logical or, "^" is logical not.
Python implements regular expression searching and replacing in the standard-library module re (see also this tutorial). Here are the basics:
the method
re.search(pattern,string,[flags])returnsNoneif there is no match, or a match object that can be queried with its methodgroup(); for instance>>> import re >>> m = re.search('([0-9]*)/([0-9]*)/([0-9]*)','7/15/1973') >>> m <_sre.SRE_Match object at 0x1002e2880> >>> m.group(0) # entire matching expression '7/15/1973' >>> m.group(1), m.group(2), m.group(3) # individual groups ('7', '15', '1973')- useful
flagsincludere.DOTALL, which makes "." match against a newline, andre.IGNORECASE, which makes matching case-insensitive; the method
re.sub(pattern,repl,string)searches forpatterninstring, and replaces it withrepl; ifpatterncontains groups, these can be called up inreplas\[numeral]. For instance>>> re.sub('Hello, (.*)',r'Goodbye, \1','Hello, Michele') 'Goodbye, Michele'- the method
re.findall(pattern,string)returns a list of all the matching substrings instring; ifpatternincludes a group, thenre.findallreturns a list of the matched groups; ifpatternincludes multiple groups, thenre.findallreturns a list of tuples of matched groups; in Python strings, the backslash "
\" serves to form escape sequences such as "\n" (newline), "\t" (tab), and "\\" (the backslash itself). So to match "*" we'd use the Python string'\\*', and to match a single backslash we'd use'\\\\'. Therein lies madness, so instead we use Python's raw strings (such asr'\\'), in which backslashes are handled as regular characters;
References
Friedl, J. E. F. 2006. Mastering Regular Expressions, 3rd ed. Sebastopol, CA.